Blog

Apr 16, 2024
Strategies for Reducing Data Warehouse Costs: Part 3
Decrease your data warehouse costs by sinking precomputed results and leveraging real-time analytics.
Apr 16, 2024
Strategies for Reducing Data Warehouse Costs: Part 2
Here's how to save money on your data warehouse bill with normalized data models and data mesh principles.
Apr 9, 2024
Strategies for Reducing Data Warehouse Costs: Part 1
With Materialize, teams can lower the cost of their data warehouse bill and implement new use cases.

Apr 8, 2024
Announcing our new CEO: Nate Stewart
Materialize welcomes new CEO Nate Stewart, who previously served on the Materialize board and comes to us from Cockroach Labs.

Mar 19, 2024
Materialize + Redpanda Serverless: Simplified developer experience for real-time apps
Combining Redpanda Serverless with Materialize makes developing streaming data apps easier than ever before.

Mar 15, 2024
Native MySQL Source, now in Private Preview
Access the freshest data in MySQL to power your operational workflows

Mar 7, 2024
Real-Time Fraud Detection: Analytical vs. Operational Data Warehouses
In this blog, we’ll explain the different roles of analytical and operational data warehouses in building real-time fraud detection systems.

Mar 5, 2024
View your usage and billing history
Get complete visibility into your usage trends and billing history to manage your spend effectively
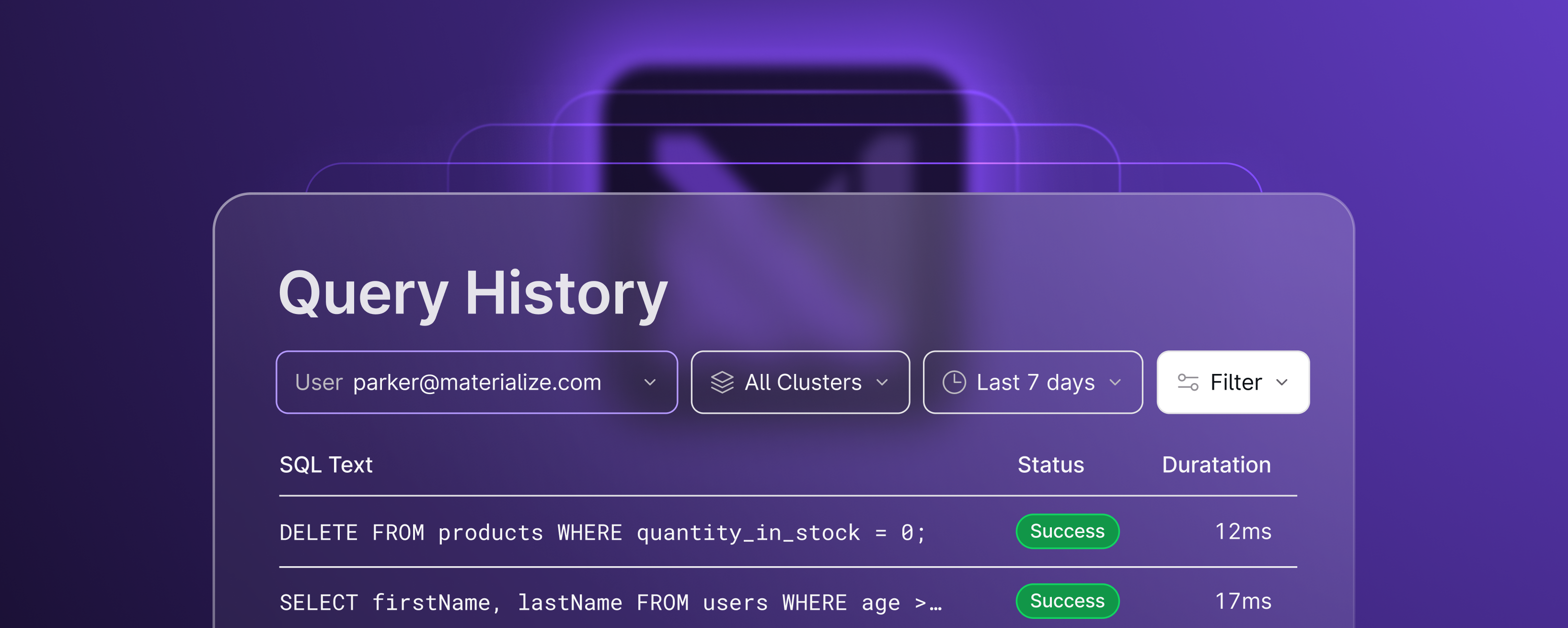
Feb 29, 2024
Introducing Query History
Now in Private Preview, Query History lets you monitor your SQL query performance to detect potential bottlenecks
Feb 23, 2024
Data Freshness: Why It Matters and How to Deliver It
Data freshness is essential for real-time business use cases. Here's how an operational data warehouse powers your business processes with fresh data.

Feb 12, 2024
Doing business with recursive SQL
Learn how recursive SQL provides an elegant solution for a fundamental use case in economics - stable matching.

Feb 2, 2024
What is an operational data warehouse?
Learn how an operational data warehouse enables organizations to use their freshest data for day-to-day decision-making

Jan 26, 2024
What is a real-time analytics database?
Discover the essentials of real-time analytics databases, their benefits, and how they compare to traditional databases for better operational decision-making.

Jan 19, 2024
Materialize and Advent of Code: Using SQL to solve your puzzles!
The Materialize team participated in Advent of Code 2023 and took a bold approach in using SQL to solve each puzzle. Check it out.

Jan 11, 2024
Responsiveness and Operational Agility
See how Materialize supports operational work with responsiveness.

Oct 16, 2023
VS Code Integration Guide | Materialize
Integrate Materialize with VS Code for schema exploration, SQL validation & query execution, all within your IDE for efficient development.

Oct 12, 2023
Freshness and Operational Autonomy
At the heart of freshness in Materialize is autonomous proactive work, done in response to the arrival of data rather than waiting for a user command.

Sep 28, 2023
Announcing Webhook Sources
Today Materialize customers can create webhook sources, making it much easier to pipe in events from a long tail of SaaS platforms, services, and tools.

Sep 26, 2023
Consistency and Operational Confidence
Materialize's consistency guarantees are key for confidence in data warehouses. Understand the benefits & see real-world tests in action.

Sep 22, 2023
A guided tour through Materialize's product principles
Take a guided tour through Materialize's three pillars of product value, and see how we think about providing value for your operational workloads.

Sep 12, 2023
Operational Data Warehouse Overview | Materialize
We've built Materialize as a new kind of data warehouse, optimized to handle operational data work with the same familiar process from analytical warehouses.
Aug 31, 2023
RBAC now available for all customers
Comprehensive RBAC for Materialize users ensures secure, production-grade environment management & access control.

Aug 29, 2023
Lower Data Freshness Costs for Teams | Materialize
Materialize has a subtly different cost model that is a huge advantage for operational workloads that need fresh data.

Aug 1, 2023
Capturing Change Data Capture (CDC) Data
An illustration of the unexpectedly high downstream cost of clever optimizations to change data capture.

Jul 27, 2023
Cloud Data Warehouse Uses & Misuses | Materialize
Data Warehouses are great for many things but often misused for operational workloads.

Jul 18, 2023
Confluent & Materialize Expand Streaming | Materialize
Materialize & Confluent partnership offers SQL on Kafka capabilities for efficient data team integration.

Jul 12, 2023
Recursive SQL Queries in Materialize | Materialize
Support for recursive SQL queries in Materialize is now available in public preview.

Jun 2, 2023
Shifting Workloads from Data Warehouses | Materialize
A framework for understanding why and when to shift a workload from traditional cloud data warehouses to Materialize.

May 18, 2023
Real-Time Postgres Views Updates | Materialize
Major updates to PostgreSQL streaming replication allow for real-time & incrementally updated materialized views with Materialize.

May 11, 2023
When to use Materialize vs a Stream Processor
If you're already familiar with stream processors you may wonder: When is it better to use Materialize vs a Stream Processor? And why?

Apr 25, 2023
A Terraform Provider for Materialize
Materialize maintains an official Terraform Provider you can use to manage your clusters, replicas, connections and secrets as code.

Apr 20, 2023
Everything you need to know to be a Materialize power-user
Master Materialize for enhanced scale, performance & power with key internal insights. A guide for aspiring power-users.

Apr 5, 2023
The Four ACID Questions
Four questions, and their answers, to explain ACID transactions and how they are handled within Materialize.

Mar 9, 2023
Towards Real-Time dbt
A framework for reducing the time between raw data availability & its transformation with dbt for customer value.
Feb 23, 2023
The Software Architecture of Materialize
Materialize aims to be usable by anyone who knows SQL, but for those interested in going deeper and understanding the architecture powering Materialize, this post is for you!

Feb 16, 2023
When to Use Indexes and Materialized Views
If you are familiar with materialized views and indexes from other databases, this article will help you apply that understanding to Materialize.

Jan 31, 2023
Clusters, explained with Data Warehouses
If you're familiar with data warehouses, this article will help you understand Materialize Clusters in relation to well-known components in Snowflake.

Jan 18, 2023
Delta Joins and Late Materialization
Understand how to optimize joins with indexes and late materialization.
Jan 11, 2023
Recursion in Materialize
Understanding recursion in Materialize & its significance in differential dataflow for SQL updates.

Oct 19, 2022
Real-Time Customer Data Platform Views on Materialize
Let's demonstrate the unique features of Materialize by building the core functionality of a customer data platform.

Oct 18, 2022
How and why is Materialize compatible with PostgreSQL?
As an operational data warehouse, Materialize is fundamentally different on the inside, but it's compatible with PostgreSQL in a few important ways.

Oct 3, 2022
Announcing the next generation of Materialize
Today, we’re excited to announce a product that we feel is transformational: a persistent, scalable, cloud-native Materialize.
Jul 27, 2022
Indexes: A Silent Frenemy
Insights on how indexes impact scaling in databases & their evolution in streaming-first data warehouses.

Jul 14, 2022
Real-time data quality tests using dbt and Materialize
Real-time SQL monitoring & data quality tests with dbt & Materialize for continuous insights as data evolves.

Jun 15, 2022
Managing streaming analytics pipelines with dbt
Let's explore a hands-on example where we use dbt (data build tool) to manage and document a streaming analytics workflow from a message broker to Metabase.

Jun 14, 2022
Virtual Time for Scalable Performance | Materialize
The key to Materialize's ability to separate compute from storage and scale horizontally without sacrificing consistency is a concept called virtual time.

Jun 9, 2022
Let’s talk about Data Apps
What is a Data Application? How do they help our customers? What new challenges do we face when building Data Apps? Here's our perspective.
May 13, 2022
Announcing the Materialize Integration with Cube
Connect headless BI tool Cube.js to the read-side of Materialize to get Rest/GraphQL API's, Authentication, metrics modelling, and more out of the box.

May 6, 2022
Materialize's unbundled cloud architecture
Materialize's new cloud architecture enhances scalability & performance by breaking the materialized binary into separate services.

Apr 25, 2022
Creating a Real-Time Feature Store with Materialize
Materialize provides a real-time feature store that updates dimensions with new data instantly & maintains speed & accuracy.

Mar 3, 2022
Subscribe to changes in a view with Materialize
Real-time SQL query & view update subscriptions are made simple with Materialize's SUBSCRIBE feature.

Mar 1, 2022
What's new in Materialize? Vol. 2
Comprehensive updates in Materialize Vol. 2: AWS roles, PostgreSQL enhancements, Schema Registry SSL, & more for streamlined data management.

Jan 19, 2022
Introducing: Tailscale + Materialize
Materialize Cloud integrates with Tailscale, offering secure & easy connection of clusters to private networks using WireGuard protocol.
Dec 20, 2021
What's new in Materialize? Volume 1
Stay updated with Materialize: Kafka source metadata, protobuf & schema registry integration, time bucketing, Metabase, cloud metrics & monitoring enhancements.

Oct 19, 2021
Stream Analytics with Redpanda & Materialize | Materialize
Enhance your data workflows with Redpanda & Materialize for faster & more efficient streaming analytics. Get insights on integration & usage.

Sep 30, 2021
Materialize Secures $60M Series C Funding | Materialize
Materialize raises another round of funding to help build a cloud-native streaming data warehouse.

Sep 21, 2021
Change Data Capture is having a moment. Why?
Change Data Capture (CDC) is finally gaining widespread adoption as a architectural primitive. Why now?

Sep 13, 2021
Materialize Cloud Enters Open Beta
Materialize Cloud, now in open beta, offers real-time data warehousing for immediate insights & action on live data.

Aug 27, 2021
Release: 0.9
Materialize's Release 0.9 introduces an Operational Data Warehouse optimized for real-time data actions & cloud efficiency.

Aug 5, 2021
Materialize & Datalot: Real-time Application Development
Materialize & Datalot collaborate on cutting-edge real-time application development, leveraging streaming data for immediate insights & action.

Jun 14, 2021
Release: 0.8
Comprehensive insights & updates on Materialize's Release 0.8, enhancing real-time data warehousing capabilities for immediate action.

Jun 2, 2021
Maintaining Joins using Few Resources
Efficiently maintain joins with shared arrangements & reduce resource usage with Materialize's innovative approach.

Apr 27, 2021
Join Kafka with a Database using Debezium and Materialize
Debezium and Materialize can be used as powerful tools for joining high-volume streams of data from Kafka and tables from databases.

Apr 21, 2021
Real-time A/B Testing with Segment & Kinesis | Materialize
Build a real-time A/B testing stack with Segment, Kinesis and Materialize.

Mar 24, 2021
dbt & Materialize: Streamline Jaffle Shop Demo | Materialize
Let's demonstrate how to manage streaming SQL in Materialize with dbt by porting the classic dbt jaffle-shop demo scenario to the world of streaming.

Mar 9, 2021
Release: 0.7
Comprehensive insights & updates in Materialize's Release 0.7, enhancing real-time data warehouse capabilities.

Mar 1, 2021
How Materialize and other databases optimize SQL subqueries
Insight into SQL subquery optimization & how Materialize's approach differs from other databases, enhancing query performance.
Mar 1, 2021
Introducing: dbt + Materialize
Efficient SQL data transformations & real-time analytics with dbt + Materialize: a powerful operational data warehouse combo.

Feb 16, 2021
Temporal Filters: Enabling Windowed Queries in Materialize
Temporal filters give you a powerful SQL primitive for defining time-windowed computations over temporal data.

Jan 20, 2021
Efficient Real-Time App with TAIL | Materialize
Let's build a python application to demonstrate how developers can create real-time, event-driven experiences for their users, powered by Materialize.

Jan 14, 2021
Slicing up Temporal Aggregates in Materialize
Comprehensive guide on slicing temporal aggregates with Materialize for real-time data analysis & actionable insights.

Jan 7, 2021
Release: 0.6
Materialize's Release 0.6 enhances cloud data warehousing with real-time streaming capabilities for immediate action on live data.
Dec 14, 2020
Joins in Materialize
Comprehensive guide to implementing joins in Materialize, covering binary to delta joins for efficient streaming systems.

Dec 8, 2020
Kafka is not a Database
In principle, it is possible to use Kafka as a database. But in doing so you will confront every hard problem that database management systems have faced for decades.

Dec 2, 2020
Live Maintained Views on Boston Transit to Run at Home
Real-time apps for Boston Transit with live data are easy to set up using Materialize; see two examples you can run at home.

Nov 30, 2020
Materialize Raises a Series B
Materialize secures Series B funding to enhance its Operational Data Warehouse with real-time streaming capabilities for immediate data action.

Nov 24, 2020
Release: Materialize 0.5
Materialize 0.5 operational data warehouse offers real-time action on live data for efficient & immediate insights.

Sep 30, 2020
Materialize under the Hood
An in-depth look at Materialize, the Operational Data Warehouse with streaming capabilities for real-time data action.

Aug 18, 2020
Lateral Joins and Demand-Driven Queries
Comprehensive guide to using Materialize's LATERAL join for efficient query patterns in incremental view maintenance engines.

Aug 13, 2020
Change Data Capture (part 1)
Here we set the context for and propose a change data capture protocol: a means of writing down and reading back changes to data.

Aug 11, 2020
Why Use a Materialized View?
Materialized views offer cost-efficient querying by storing results in memory & updating only as needed, perfect for optimized data management.

Aug 6, 2020
Why not RocksDB for streaming storage?
An explanation of our rationale for why Materialize chose not to use RocksDB as its underlying storage engine.

Aug 4, 2020
Robust Reductions in Materialize
Comprehensive guide to implementing robust reductions in Materialize, ensuring efficient & real-time data processing.

Jul 28, 2020
Release: Materialize 0.4
Materialize 0.4 introduces an Operational Data Warehouse with real-time streaming capabilities for immediate data action & analysis.

Jul 14, 2020
Eventual Consistency isn't for Streaming
Understand why eventual consistency isn't suitable for streaming systems & the systematic errors it can cause with Materialize's insights.

Jun 11, 2020
Streaming Database Roadmap Guide | Materialize
A guide to creating a streaming database with Materialize, from using a streaming framework to developing a scalable platform.

Jun 8, 2020
CMU DB Talk: Building Materialize
Arjun Narayan introduces the CMU DB group to streaming databases, the problems they solve, and specific architectural decisions in Materialize.

Jun 1, 2020
Release: Materialize 0.3
Materialize 0.3, an Operational Data Warehouse with cloud & streaming capabilities, optimizes real-time data action.

May 5, 2020
Managing memory with differential dataflow
Insights on how Differential Dataflow manages & limits memory use for processing unbounded data streams, ensuring efficiency.
Mar 31, 2020
Consistency Guarantees in Data Streaming | Materialize
Understand the necessary consistency guarantees for a streaming data platform & how they ensure accurate data views.

Mar 27, 2020
Upserts in Differential Dataflow
Comprehensive guide to implementing upserts in differential dataflow with Materialize for real-time data warehouse optimization & efficiency.

Mar 24, 2020
What’s inside Materialize? An architecture overview
Let's review the internal architecture of Materialize, starting with the some context of how it's different than other databases.

Mar 18, 2020
Taking Materialize for a spin on NYC taxi data
Experience real-time data analysis with Materialize on NYC taxi data, showcasing a practical application of streaming SQL.

Feb 24, 2020
View Maintenance: A New Approach to Data Processing
Materialize's approach to data processing & view maintenance offers real-time insights for immediate action on live data.
Feb 20, 2020
Materialize Beta: The Details
Materialize Beta offers insights on a cloud data warehouse with real-time streaming capabilities for immediate action on current data.
Feb 18, 2020
Introducing Materialize: the Streaming Data Warehouse
Materialize offers a streaming data warehouse for real-time analytics & interoperability with millisecond latency, revolutionizing data handling.