



The data warehouse exists because you have so many disparate sources of data. You have data in your OLTP source of truth database, but you also have SaaS products, events, logging exhaust, and honestly probably some other OLTP databases now that you mention it. These data are all relevant, valuable, actionable, but none of these sources know how to play nice with each other. All this data goes to your warehouse because that is your first opportunity to bring this data together. The data warehouse provides value because it brings together data that otherwise could not be jointly queried. But that is not without trade-offs in latency, freshness, and correctness.
These trade-offs don’t matter for a large class of work. Traditionally, this includes analytical work: grinding through reams of historical data, producing reports, and generally looking at what has already happened. But today, data warehouses increasingly are put to use for operational work: providing interactive access to up-to-date data, automating actions on certain events, and generally reacting to things that have just happened. For operational work, organizations can’t afford slow, stale, or incorrect data.
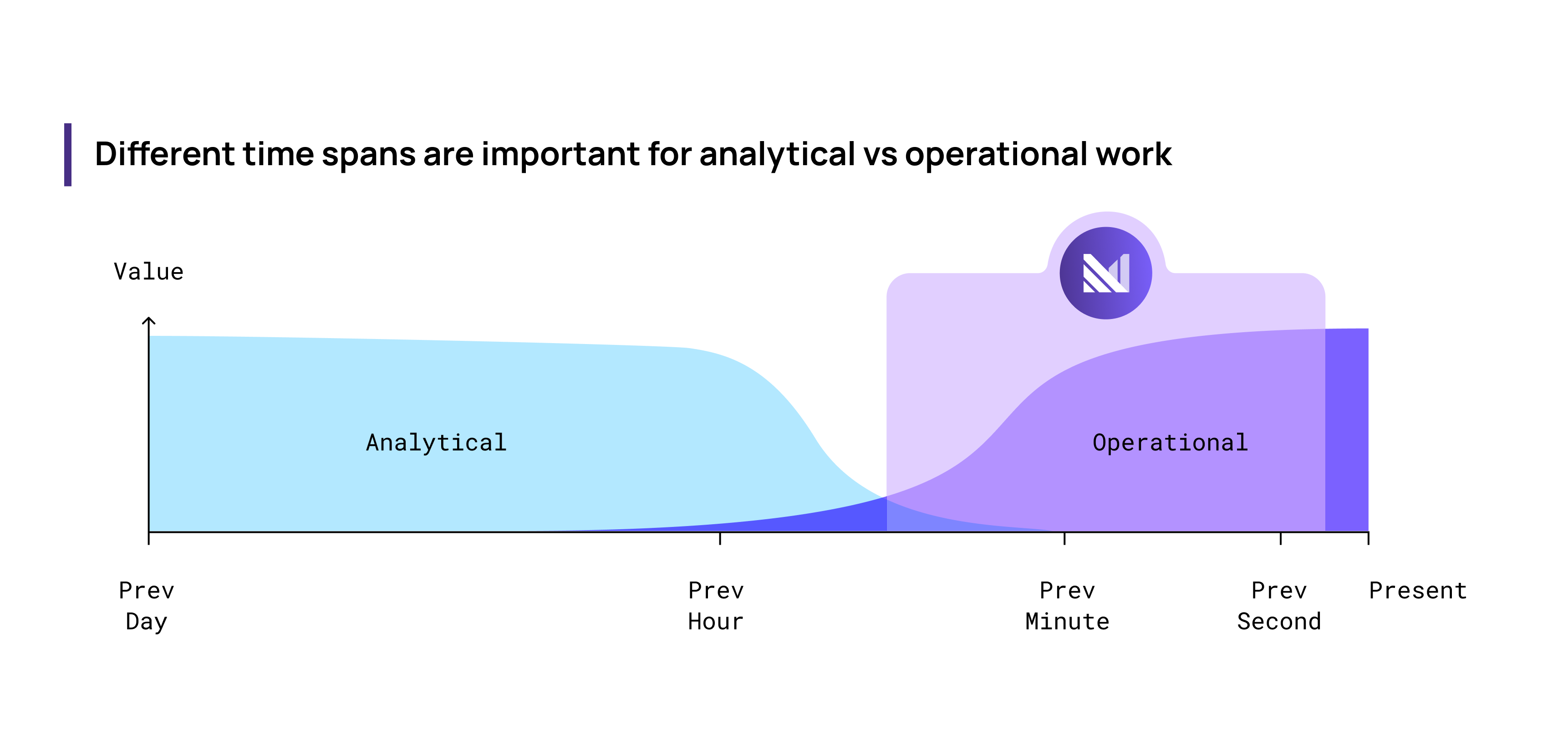
The increasing value of operational work drives some organizations to rebuild their entire workflow from scratch on stream processing platforms, but we think that data teams can be successful with operational work with tools that have the right form factor.
To understand why, let’s start by looking at what existing data warehouses got right.
The Analytical Data Warehouse
You are probably familiar with the analytical data warehouse. It’s designed to grind through reams of historical data and efficiently produce periodic reports. You may have tried to apply such a thing to operational tasks because you put your operational data there and you have a real need. And odds are, you probably discovered that the analytical data warehouse isn’t a perfect fit for your operational tasks.
The analytical data warehouse lacks several features that are critical for operational work. It’s not always up to date, because it works so hard when ingesting data. It’s not always immediately responsive, as queries work their way through queues and read from disk or cloud storage. Its contents are not always consistent, and must be manually refreshed by different tools or teams. Fundamentally, the analytical data warehouse wasn’t designed for doing operational work.
This hasn’t stopped people from wanting and trying to use conventional data warehouses for operational work, but the results are a mix of pain, frustration, and cost.
The Operational Data Warehouse
What if you had a data warehouse built for operational workloads? One where data are ingested continually, and are immediately available to query. One where query workloads are proactively updated, rather than stale until re-run. One where updated results are communicated to downstream systems that can react immediately. What if you could run operational workloads out of your data warehouse?
That’s certainly what we wanted with Materialize, and it is the best framing of what we’ve built.
Architecturally, an operational data warehouse (such as Materialize) sits just upstream of your conventional analytical data warehouse. It receives data as they happen, and can transform, normalize, and enrich the data as they land. It can immediately act on the data, including updating maintained views and indexes, and informing downstream dependencies. It can promptly respond to ad-hoc queries against up-to-date data. The data can be replicated to an analytical data warehouse for longer-term storage and analysis, and when appropriate are retired from the operational data warehouse.
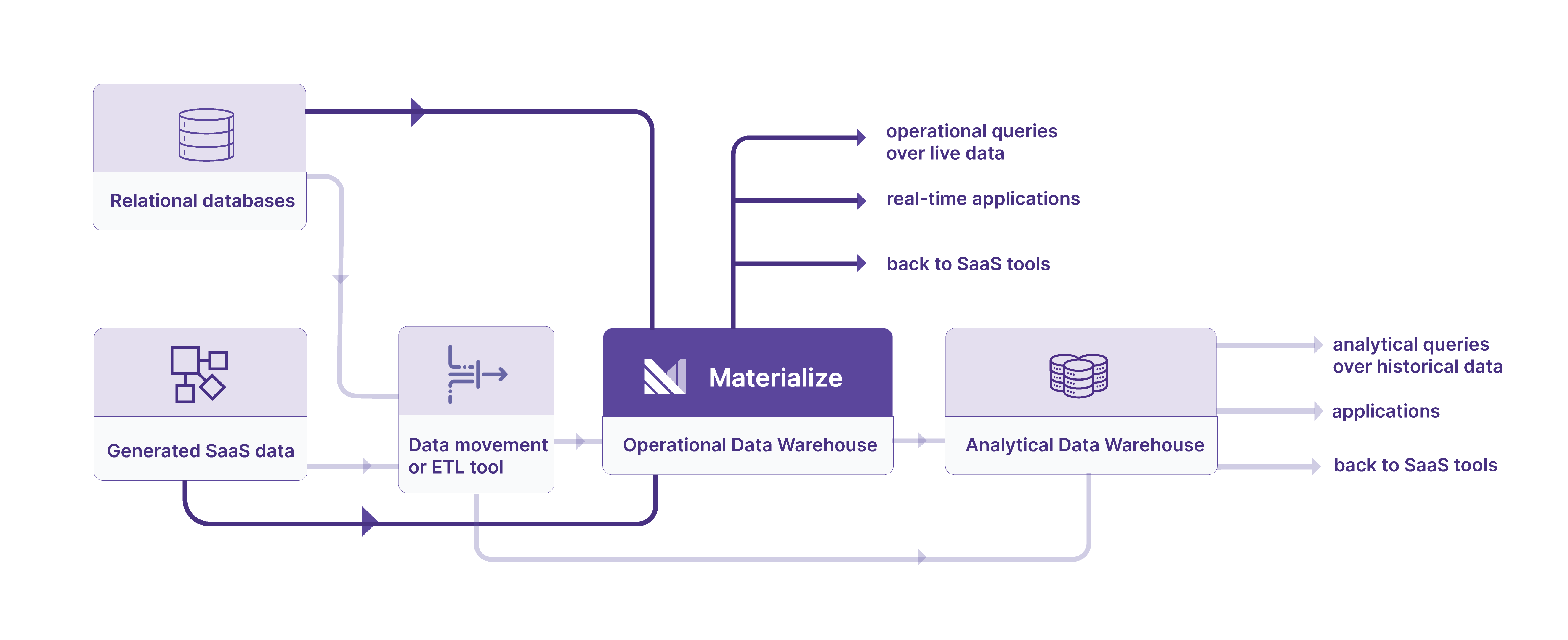
You should want to use an operational data warehouse as you would a team of your top human operators. You must be able to trust it to get your work done promptly, correctly, and autonomously. It needs to scale to absorb arbitrary volumes of work. It needs to be easy to work with; both clear in communicating what it should do and unsurprising in its outcomes. You should be able to rely on an operational data warehouse to get operational work done.
Materialize: An Operational Data Warehouse
As we built Materialize as an operational data warehouse, we focused on those three foundational elements: trust, scale, and ease.
Materialize views trust as a combination of interactivity, freshness, and consistency. It must be responsive, minimizing the time between an operational ask and its completion. It must be up to date, immediately reflecting updates to your data as soon as they happen. It must be consistent, presenting answers and taking actions that always check out. These properties combine to make Materialize a trusted surrogate data operator.
Materialize scales in multiple independent and important dimensions. It scales up within a use case through a data-parallel data processor that can involve multiple cores and computers. It scales out across arbitrarily many use cases through storage and compute isolation. It even scales down to a single core if that is all your use case needs. This flexibility means Materialize can absorb all shapes of work, but only spends in proportion to their requirements.
Materialize is as easy as a strictly serializable SQL database. Data arrive and are presented as continually changing tables, over which you use SQL to frame views describing your business logic, and atop which you build indexes that provide ready access to fresh results. Materialize works hard to keep these views up to date, but you experience this only through surprisingly prompt and fast access to indexed view contents. Interactive query results come back in strict serialized order, as if all were executed in order one at a time, avoiding the otherwise complex application logic you need to avoid tripping over inconsistent results.
Internally, Materialize is built around sophisticated, award-winning streaming technology that enables these three characteristics. However, the value of Materialize is that you get to benefit from this streaming technology without needing to deeply understand it. Streaming is just an implementation detail, rather than the product category. Materialize presents as a trustworthy, scalable, and easy-to-use data warehouse that just happens to be adept at operational work.
But are you excited?
We are excited about Materialize’s potential as an operational data warehouse. Join us, and some of our customers, in the coming weeks: at Current in San Jose to see how Pluralsight is using Materialize to power their Plan Analytics product, and at dbt Coalesce in San Diego to see how Ramp is using Materialize to operationalize their fraud detection pipelines.
How can you know if an operational data warehouse is a good fit for you? What all our customers have in common is that bringing their continually changing data together into one location provides the coordination benefits that databases and conventional data warehouses provide. As just a few examples:
- A shared storage layer means that all of your users and use cases will see consistent data, produce always consistent intermediate data products, and share and interact without any is-this-data-current coordination.
- Shared indexed data (like a database has, but in a data warehouse!) means new use cases can re-use existing data assets and deploy both quickly and at low marginal cost.
- Shared catalog state means that your teams are working against the same models and view definitions, just as they are against the same data.
These are just a few of the exciting features that spill out when you architect for operational work.
Try Materialize!
If you’re ready to try out Materialize for your operational workloads, you can register for an account today. If you’d like to connect to learn more first, you can find a time to get a demo from our team and see if Materialize is the right fit for you.
info
Join us for a live stream
Join Materialize cofounders Arjun Narayan and Frank McSherry on September 20th for a live walkthrough of operational data warehouses, and how data teams at companies like Ramp, Pluralsight, General Mills are shipping operational data products on them.
Register
