

Today we will take a bit of a tour of the moving parts that make up Materialize. This tour isn’t meant to be exhaustive, but rather to show off some of the moments where things might be different from what you expect, and to give you a sense for why Materialize is relatively better at maintaining SQL queries over changing data. In particular, how it provides interactive access to up-to-date data, how it does this using fewer resources than you might expect, and how it is operationally simpler than other approaches.
In Broad Strokes
Let’s start with some broad strokes that name the moving parts of the system. We will use the following schematic diagram:
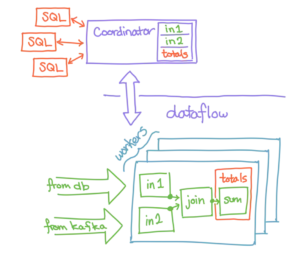
Users interact with Materialize primarily through a pgwire-esque front end, with SQL commands that create, query, and remove data sources, views, and materializations. These commands make their way to the coordinator, whose job it is to track the metadata about these sources, views, and materializations, and to communicate with the dataflow layer about what it should be doing next. The dataflow layer is responsible for the execution and maintenance of the views the coordinator provides it.
We’ll dive in to each of these in increasing detail. Mostly, they are increasingly different from existing infrastructure, and so there is more that needs to be said as we go deeper down. I’m also more familiar with the deeper down stuff myself; we’ll need to get some other folks to explain how Materialize adapts to existing SQL idioms and expectations.
Front end
We have intentionally aimed to make Materialize’s user interfaces as uninteresting as possible. The more conventional these interfaces, the more existing tools and use cases can directly connect to Materialize and get moving, without new SDKs or programming effort. You can use psql to directly connect to Materialize, or BI tools like Metabase for an enriched experience. From the outside, we want Materialize to look and feel like the database you and your data infrastructure expect.
Concretely, this means that your (or tools on your behalf) establish sessions, in which you CREATE, SELECT from, TAIL, and DROP various objects. You can read about the full vocabulary in the Materialize documentation. Your session will pass your commands along to the coordinator, who determines whether they make sense, and what sort of response to provide.
The Coordinator
Just behind the user interfaces lives the coordinator, the brains of Materialize. This is where we track information about the sources of data you (and other users) have installed, views you have created over them, and the materializations we maintain for you. Here we parse, plan, and optimize your SQL queries, and when appropriate instruct the dataflow layer to spin up a new computation to execute and maintain their results. The coordinator also tracks the state of materializations, and ensures that we take advantage of them when planning how to answer and maintain new queries.
When your queries arrive they are little more than SQL text, and need to be parsed, planned, and optimized. This process is largely well-understood, if fraught with semantic peril, but there are some quirks that are Materialize-specific. The cost of maintaining a dataflow can be very different from the cost of executing a query once. Materialize queries will be executed as long-lived stateful dataflow, and impose an ongoing cost of computation and memory. As input data change, we want to quickly respond and cannot afford a full query re-evaluation. This results in an optimization process that has different priorities than traditional optimizers.
The coordinator is also responsible for tracking the properties of the materializations we maintain. Materializations are of some collections of data, and they are arranged by some keys (often columns). These two characteristics tell the coordinator whether a materialization can assist in the construction and maintenance of a new dataflow. The use and re-use of materialized data lie at the heart of what makes Materialize different from existing systems.
Ultimately, the main role of the coordinator is to provide instruction to the dataflow layer, which is where the dataflow computations for queries are assembled and maintained, and is where the data backing the materializations are housed.
Dataflow Execution
If the coordinator is the brains that thinks about what data processing to do, the dataflow layer is the muscle that makes it happen. The dataflow layer houses the main departures from standard relational databases, and from the stream processing engines you might be most familiar with.
Our dataflow layer is built over timely dataflow and differential dataflow, scalable data-parallel dataflow frameworks designed to process information as efficiently as we know how. Significantly, these frameworks are designed to capture and share state across multiple dataflows, using a tool called shared arrangements: the streaming dataflow equivalent of relational database indexes. We will explain what these are, and connect the dots to maintaining SQL queries over changing data.
In timely dataflow, multiple worker threads cooperate to execute and maintain multiple dataflows. Each worker thread knows about all dataflows, and can perform the logic for any of the operators; the routing of data to individual workers determines where the work actually occurs and where state is held. This is different from many big data systems, which isolate each operator on its own thread or computer.
Key Concept 1 Materialize’s design decouples the complexity of your queries from the complexity of your deployment. You can maintain hundreds of queries on a single machine, and scale up to more machines only when you want to.
When multiple workers cooperate on a computation, particularly a fast-moving computation, they run the risk of introducing chaos. Traditional mechanisms from databases, regular locking and coordination between the threads, negatively impact scalability and throughput. Traditional mechanisms from streaming systems isolate the units of work to be done, which limits the ability to share resources across dataflows. In materialize, we want to provide both scalability and economy, and need to use clearer coordination mechanisms.
All updates in Materialize bear a logical timestamp, an unambiguous indication of when the update “takes place”. This timestamp could be the wall-clock time, or it could be a transaction identifier from your database; you can choose its meaning. All operators preserve this logical timestamp in their output, and thereby maintain a consistent view of the results. Query results are always correct with respect to this timestamp, and never out of sync with one another, even though their execution is asynchronous and across multiple parallel workers.
Key Concept 2 Logical timestamps allow Materialize to provide deterministic, always consistent query results, without requiring fine-grained coordination between workers, nor isolation between their work items.
Timely dataflow’s design allows our worker threads to share worker-local state and computation across dataflows. This brings the database concept of a shared index to the world of streaming computation, and with it interactive analysis of always fresh data. Let’s see an example of how that works.
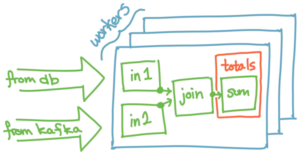
In this example dataflow, taken from our overview up above, there is a collection totals that is defined by a query that joins two inputs and aggregates up the results. The result is an in-memory materialization of the results, a “shared arrangement”, boxed above in orange. This materialization is indexed by whatever key was used for the aggregation, the SQL GROUP BY keys perhaps, and it is continually maintained as its input data change. Like a database index, the materialization provides random access to its data, and can dramatically improve the performance of new queries that would have to reprocess their inputs in other systems.
If we want to use it in a new query, it is all ready to go without needing to reprocess any of its inputs. You can get immediate random access to it, and set up new dataflows that depend on it without rebuilding it for each dataflow.
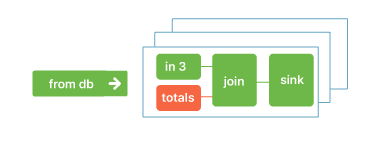
This new dataflow is built using the in-memory shared arrangement, rather than re-reading (or worse, re-computing) the totals collection. We also re-use the work done to maintain the arrangement as the underlying data change. Any number of queries can re-use the same arrangement, and the cost of each query is determined only by the new work it introduces.
Key Concept 3 Materializing results in shared arrangements provides the low query latency and resource efficiency of relational database indexes, while retaining the scalable architecture of data-parallel dataflow systems.
There is certainly a lot going on in Materialize, but these three concepts stuck out to me as the basis for why you might expect something different here. They enable a qualitatively different data analysis experience, with fast queries, fast updates, all at the scale that is appropriate for you.
Limitations
It is reasonable to wonder what Materialize’s limitations might be, given its several advantages. Informally, a system like Materialize that shares maintained state optimizes for this use case more than for other use cases. Computations that do not need to maintain their results might be better implemented by polling a more traditional data processor, performing work only when asked. Computations that do not need (or expect) to share state might better execute each query de novo using the fastest possible technology for reading data (e.g. columnar stores). We’ve put our effort in to the use case we think is most underserved, efficiently maintaining big data computations, and that comes at the expense of not building something else.
That being said, we’ve had a great reaction from users who report that Materialize’s combination of interactive, and always up to date analysis match both their needs and expectations. We’ve got enough new stuff going on here that we are pretty comfortable being candid about the limitations, so take it for a spin and tell us what you think!
In Conclusion
Materialize is a system designed to maintain relational queries over continually changing data. It has several specific advantages over other systems that make it better suited to this task. Specifically, Materialize is well-equiped to maintain indexed representations of collections of data as they change, and to leverage these indexes in maintaining queries over relational data. It blends the benefits of relational database indexes with the scalability and performance of stream processors. All of this, with a familiar SQL front-end that works the way you would expect it to work.
If you’d like to see how well Materialize works for you, register for a Materialize account here to get started!