

A roadmap for a storage engine for Materialize
As my final task as an engineer at Cockroach Labs, I wrote a blog post titled “Why we built CockroachDB on top of RocksDB”, where I discussed the extensive reasons that RocksDB was a good choice for CockroachDB’s storage engine at the time. So I suppose it was inevitable that I’d end up explaining why we chose a different approach for building state management in Materialize.
Materialize does not use RocksDB as its underlying storage engine. However, several other streaming frameworks do, such as Flink and Kafka Streams/KSQL (but not all: Spark Streaming uses the same Resilient Distributed Datasets storage layer as Spark, as it’s essentially Spark run in a micro-batched fashion). Given my past positive experience using RocksDB as a storage engine for an OLTP database, and given that RocksDB is the default choice for state manager in streaming systems, why did we choose not to use it in Materialize?
A RocksDB Primer
RocksDB is an embeddable storage engine that uses a log-structured merge tree of immutable flat files as the underlying index data structure. RocksDB maintains this indexed representation to efficiently perform point lookups, inserts, and range scans. RocksDB also provides support for strong isolation guarantees when performing those operations, and does so at high performance when there are multiple concurrent readers and writers accessing the same state, all while continuing LSM compaction in additional background threads.
This is an excellent storage engine to base OLTP workloads on top of, which is why several systems with primarily OLTP considerations all build on top of RocksDB: such as CockroachDB, YugabyteDB, and TiKV (and TiDB). Stream processors have followed this trend: Flink, Kafka Streams, and others. Why do we not repeat this (tried and tested) experience, thus saving valuable engineering time? My position is that while RocksDB is a great OLTP storage engine, it is not a great fit for streaming.
The Timely Dataflow Computational Model
Timely Dataflow: Sharding and Scheduling
Before we talk about this, we have to spend a little bit of time on Timely Dataflow, the streaming engine at the heart of Materialize. Timely Dataflow is a radically different framework than other stream processing frameworks like Flink and Kafka Streams in its physical computational model. I describe these differences a bit in a talk I gave at Carnegie Mellon University (video and transcript here), but for a quick overview, there are a couple design choices that are relevant when it comes to persistent storage. While all the streaming engines mentioned are push-based dataflow engines (as opposed to a pull-based Volcano execution model used by several databases), there is a major design difference in the sharding pattern of the dataflow graph across distributed CPU cores.
A streaming dataflow graph is a set of operator nodes (intuitively, the familiar relational nodes like “join”, “reduce”, “map”, etc.), with streaming updates moving along the edges of the graph. When taking this logical dataflow graph and instantiating a physical set of operators, there comes an important decision in how to lay the operators out (and the inter-operator streams) across the available physical resources (the CPU cores, possibly across several machines).
Both Flink and Kafka Streams choose to divide work up by dedicating physical CPU cores to operators (the pink divider lines are separators between CPU cores, which are labeled “workers”), and sharding streams across a cluster of cores. If some logical operators require more CPUs, they can be replicated across several cores (e.g. the “count” operator in the graph below). This means that every edge flows between cores (and potentially between machines). This results in a large amount of cross-core data movement, at high cost even in the common case. These stream processors are thus severely memory bandwidth bound.
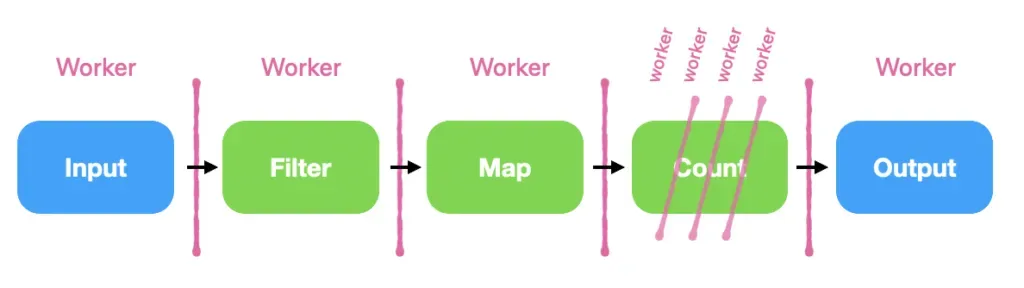 Figure 1: The Flink and Kafka Streams operator sharding pattern.
Figure 1: The Flink and Kafka Streams operator sharding pattern.
Flink and Kafka Streams use a core (or several) dedicated to each operator. In contrast, timely dataflow cores are sharded differently, intentionally to minimize cross-core data movement [1]:
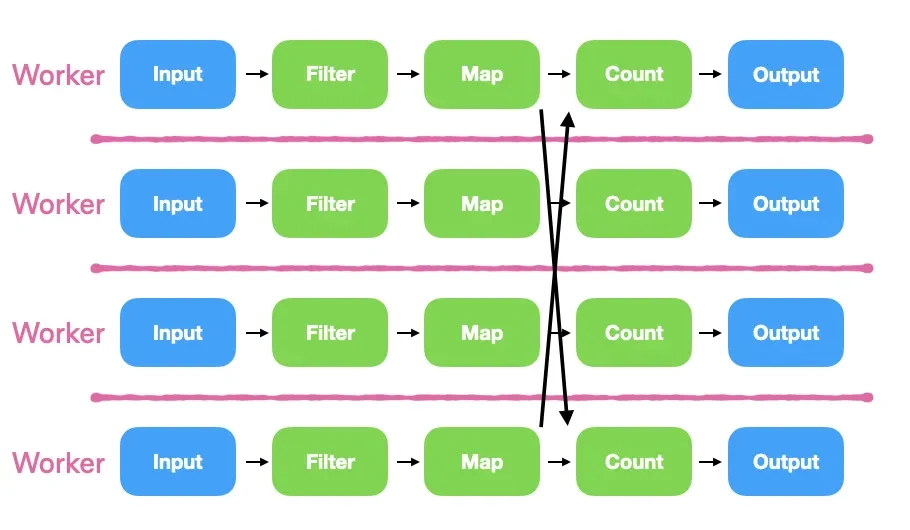 Figure 2: The Timely Dataflow operator sharding pattern.
Figure 2: The Timely Dataflow operator sharding pattern.
Each core in a Timely Dataflow cluster has a complete copy of the logical dataflow plan, and every operator is partitioned across every core. In this sharding scheme, operators on a worker are cooperatively scheduled, and have to be carefully designed to yield eagerly, or they will block other operators from executing, potentially stalling the entire dataflow graph. While this is an additional programming burden, the benefits here are that when data does not have to be exchanged, operators can execute in a fused fashion, calling in directly into the next function, with little expensive data movement. While this is not the entirety of the reason for timely dataflow’s many performance records, this attentiveness to core-local data locality means that timely dataflow elides cross-core data transfer and the cache eviction that comes along with it in many common cases. And empirically, paying careful attention to the memory hierarchy matters when building high performance concurrent systems.
And therein lies the problem with RocksDB: RocksDB is designed for liberally using background threads to perform the computation for physical compaction. In an OLTP setting, this is exactly what you want - lots of concurrent writers pushing to the higher levels of the LSM tree, lots of readers accessing immutable SSTables of the entire tree with snapshot isolation semantics, and compaction proceeding in the background with additional cores. In a streaming setting, however, those cores are better used as additional concurrency units for the dataflow execution, which means compaction happens in the foreground. And thus, scheduling when the compaction happens cannot be outsourced, and must be considered alongside all other operators.
Differential Dataflow: Arrangements and Index Maintenance
Timely Dataflow provides the scheduling and execution layer for operators, but Differential Dataflow is the library on top of Timely that has careful implementations of common relational operators. Some of these operators need to maintain large amounts of state - for instance, a JOIN on two input streams will need to maintain indexes over both streams, keyed on the join condition, to quickly do lookups.
This is where many other stream processors use a RocksDB instance to maintain these indexes, which would deploy its own cores as background threads in order to perform physical compaction. The work in maintaining an index is predominantly in the computation, not in the storage. RocksDB fits well in the paradigm where it can be viewed as another operator (“state manager”) sitting alongside the traditional relational operators (“join”, “group by”, and so on). While we have not measured the computation overhead in isolation, a research paper by Kalavri and Liagouris claims that while many stream processors use RocksDB, they “question the suitability of such general-purpose stores for streaming workloads and argue that they incur unnecessary overheads in exchange for state management capabilities”.
RocksDB is also optimized for the OLTP setting out-of-the-box, where reads typically outnumber writes 10:1. In the streaming setting, however, the read:write ratio is closer to 1:1, making the default compaction algorithms a poor fit. While in principle, this is fixable by writing a custom compaction algorithm optimized for streaming (I wrote a brief history of RocksDB on my personal blog a few years back, where I outline that compaction algorithms can largely tune LSM Trees for any read/write setting), none of the stream processors we are aware of go to this effort.
Differential Dataflow takes a different approach to building and maintaining indexes, with a custom LSM-like operator called arrange. Arrange takes immutable batches as inputs (just like RocksDB) and compacts them. The difference is that arrange is sharded by worker and cooperatively scheduled like any other timely dataflow operator, at the cost of being non-durable. The details of arrangements are covered in an upcoming VLDB paper, but carefully controlling when compactions happen is a key part of maintaining consistent low latencies in streaming updates, while also maintaining a compact memory footprint.
What about persistence?
Arrangements are an in-memory data structure. Because each worker maintains its own dedicated memory space, it gracefully spills to disk via system paging, so it is not limited to the available RAM. However, upon system crash or restart, all this state is lost.
Note, however, that index maintenance and persisting streams are (subtly) orthogonal concerns! While using RocksDB as a durable index store can provide persistence, the high performance cost of using RocksDB and incurring cross-core data movement for every datum means that this is far from a free lunch. Second, there’s also considerable work in lining up the state across all the operators precisely to facilitate recovery! To do this, for instance, Flink uses the Chandy-Lamport global synchronization algorithm, incurring latency spikes when checkpointing periodically runs (a new feature removes this latency, but is currently not consistent). Kafka Streams does not do checkpointing, meaning that state largely must be thrown away and recreated upon restart, or the details of reusing state is left as an “easy exercise for the microservice programmer”.
Our view is that if index building and maintenance is fast enough, checkpointing the indexes becomes a less important concern. Just rebuild the index on restart! This reduces persistence to the challenge of storing the raw streams, rather than storing the complex globally distributed snapshot of state, a much easier problem. Just writing down the streams to append-only files, an approach that is greatly amenable to separating compute from storage, means that stream storage can be lightweight, cheap, and fast. This is our initial approach to implementing persistence in Materialize, which we intend to release in the coming months. Eventually we will iterate on persistence to durably store index state, but our view is that optimizing restart times should be solved by… well, empirically benchmarking restart times and not solved prescriptively by checkpointing indexed state.
Decoupling index maintenance from persistence is one of several intentional design decisions we’ve made when building Materialize. While arrangements have been a core part of differential dataflow for several years in production, persistence is currently scheduled for our next release, 0.5. Meanwhile, you can check out our current 0.4 release by downloading Materialize today, checking out our source code on Github, or try out a demo in the browser!
[1] Correction: Stephan Ewen points out that Flink, unlike Kafka Streams, in some cases performs some operator fusion (see this thread). Thank you Stephan for the correction!

