


Materialize lets you ask questions about your streaming data and get fresh answers with incredibly low latency. Since announcing Materialize’s v0.1, we’ve briefly covered its functionality and how one might use it at a high level. Today we’re going to get a little more granular and talk about Materialize’s internals and architecture.
The Big Picture
We’ll start with the ending here: you want aggregates and complex queries over your streaming data maintained with low-latency. Some things you might want to ask, for example, are “how many unique visitors have been on my site in the last 5 minutes”, or “what is the total volume of dollars being sent from Costa Rica to Brazil?”
Current technology to answer these queries has some painful limitations. Most existing approaches are forced to make hard trade-offs between latency and expressiveness. Solutions can broadly be divided into three categories, each with their own trade-offs.
- Batch platforms, which provide hours-old or day-old answers, and are constrained by the frequency of the ETL process.
- Existing streaming SQL systems are limited in their capabilities, often lacking the ability to declaratively handle stateful computations like multi-way joins or handle updates and deletes without building additional microservices to manually manage state.
- Lambda architectures combine the above two pipelines, which imposes great complexity in implementation and ongoing maintenance.
Materialize, in contrast, lets you perform very complex computations over streaming data using the PostgreSQL language, giving you the flexibility and declarative ease-of-use of a SQL data warehouse, at millisecond timescales without ever having to build and maintain streaming microservices.
To accomplish this, Materialize first needs to be fed the updates from the sources you want to query at low latency. With your upstream sources connected, you can define views––which are queries you know you want to repeatedly perform––using the PostgreSQL syntax. Finally, you can query these views using regular SQL, or ask Materialize to proactively send changes back to streaming sinks.
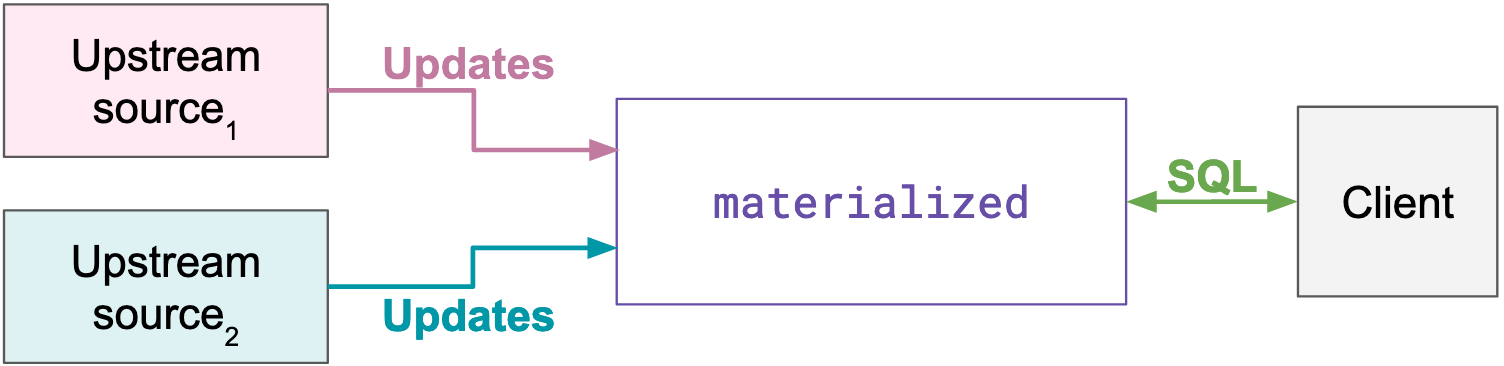
The magic happens once you define a view, and new data arrives on the sources. Materialize incrementally maintains the results of your views, in the presence of arbitrary updates and deletes on the inputs.
To understand how Materialize incrementally updates user-defined queries, we’ll look at its architecture, including:
- Defining external sources of data
- Creating and materializing views
- Maintaining materialized views as data change
External sources
We chose the name “streaming data warehouse” deliberately; one of the most important implications is that Materialize reflects data that is originally written elsewhere. So, unlike an OLTP database, Materialize doesn’t support anything like an INSERT statement (and hence doesn’t have to do transaction conflict resolution). Instead, Materialize depends on receiving data from external sources that are already ordered, for example from Apache Kafka, AWS Kinesis, or local files.
When connecting an external data source, users must describe a few of its elements:
- The type of connection that will provide raw bytes to Materialize
- The structure of the raw bytes the source provides, known as the format
- An optional envelope, which specifies whether some data should be treated as an update or a delete, or if each message is an insert to an append-only stream.
For a simple example, we could read in a locally available CSV file. In this case, we’d inform Materialize that…
- The type of connection is to a file
- The structure of the raw bytes is a CSV (i.e. ASCII text), with some number of columns
- An append-only envelope because we won’t be retracting or modifying data once we’ve inserted it
Once a user has described the external source (using CREATE SOURCE), it is available to be used in view definitions. The source cannot yet be directly inspected, because it is still just a description of where to find the data. To bring the data into the system, we’ll want to describe queries that use the data, presented as views.
Views
Materialize provides a fully-featured declarative SQL API to create and query VIEWS. Views are not a new concept: in SQL databases, they let you create a name for a particular SELECT statement––usually something complicated you don’t want to type more than once. Users can trivially use views by SELECTing from the view rather than the gnarly embedded query. However, in most systems this is just a short-hand for running the view’s SELECT statement when asked; it doesn’t go any faster than writing the same query out by hand.
Beyond the aforementioned kind of view, some databases also support something more powerful––materialized views. (You could guess that we’re excited about materialized views since we named this whole endeavor after them.) Materialized views execute once and store the result set in place of the SELECT statement; when you next query the materialized view, you quickly get access to the computed results.
Traditional databases typically only have limited support for materialized views along two dimensions: first, the refresh rate, and second, the syntax that is supported. These limitations are typically because of these databases’ limited support for incremental updates. Most databases are not designed to maintain long running incremental queries, but instead are optimized for queries that are executed once and then wound down.
This means that when the data changes, typically the materialized view must be recomputed from scratch in all but a few simple cases. Our raison d’être at Materialize is that it’s possible to do something more efficient with an advanced stream processing dataflow engine at the core: Materialize incrementally updates the view as data changes for almost all SQL queries.
Differential Dataflow
Materialize does this by building on a powerful computational framework known as Differential Dataflow. Differential, in turn, builds on top of Timely Dataflow, a powerful stateful stream processing framework. While we will write at-length about Differential and how it is radically different from other systems in a subsequent post, here we’ll aim to provide more of its gestalt than its implementation.
Timely dataflow is a distributed stream processing framework, which allows for declaring dataflow graphs of arbitrary stateful operators that receive inputs and produce outputs. Timely takes care of scheduling, message-passing, and advancing operators’ progress as the data changes. On top of timely, Differential Dataflow implements a set of declarative operators that share large amounts of indexed state and supports the full relational algebra (and more).
As sources send updates to Differential, it feeds the data through its stateful operators, ultimately generating some results. As new data continues to come in, the results are incrementally updated to reflect all of the data the dataflow has seen.
One of the key design decisions in Differential is that it only sends diffs of data. When there are no changes, nothing happens, which makes for a very efficient computational model that can deal with bursts of data, react to the changes in low latency, and then free up resources. Thinking in terms of diffs is one of the reasons that Differential is able to support arbitrary updates and deletes in the input streams. For those following closely along, this need is why we require our sources to provide an envelope for their data in order for us to be able to handle updates or deletes.
Differential Dataflows within Materialize maintain intermediate state in memory using a triply indexed structure known as “arrangements”. This is a collection key-value pair where the key describes how the values should be grouped to be most useful for consumers of the data.
An example Differential dataflow
Here’s a quick, simplified example of how Differential would handle counting a number of instances of each element it’s seen in a stream––this would be similar to the SQL statement SELECT col, COUNT(*) FROM source GROUP BY col`.`

We’ll assume that our workload is generating append-only data, denoted here that the values are all insert.

As new data comes in, our dataflow will announce its resultant changes. If we haven’t seen the values before, they will be new records for other dataflows.



However, if we have seen the value before, we instead propagate the change as an update, which means we remove the old record and insert the updated value as a new record.


This section is, like we mentioned, a dramatic oversimplification of what Differential actually does. For one example among many, Differential also maintains multi-temporal timestamps for updates––but that’s a blog post for another day.
Differential + Materialized Views
Users describe the queries they want Materialize to maintain through CREATE MATERIALIZED VIEW statements. Materialize parses the view’s embedded SELECT statement, and transforms it into a Differential dataflow.
As Materialize receives new or updated data from its external sources, the internal Differential dataflows process it as we’ve outlined above. If we’ve done our job properly, the query embedded in the materialized view will be computed and maintained. When clients want to get the query’s results, Materialize can serve them directly from the dataflow’s arrangements, meaning low-latency results that reflect recent changes.

This diagram, like many other things in this high-level overview, elides a lot of the system’s complexity. For instance, SQL clients (and therefore our SQL processing stack) must also be involved in connecting Materialized to sources. It also shows only a rudimentary system with one source and one view; in reality, it’s possible to have many sources, and many views with complex interrelations. The arrangements in particular can be shared between views, which can make a collection of views much more efficient.
Future blog posts
We hope this overview provided a general sense of how Materialize works! Beyond using Differential Dataflow cleverly to do the computation, there’s considerable work that goes on at the Materialize layer that’s meaningfully innovative and different than in a regular SQL database:
- Query planning and optimization needs to be resilient to the changing data for long-running dataflows, which means traditional cardinality estimation based planning methods are less robust. Instead, query planning in dataflow systems must choose different classes of join algorithms, which are more robust to changes in the cardinalities in the inputs.
- Even modern databases do not fully unroll query plans into static queries: a common pattern for handling subqueries, e.g. is to recursively query back into the main planning and execution engine to fire off a subquery dynamically. This is not an option for Materialize: dataflow computation systems need to fully unroll and statically determine a dataflow, which means that subquery decorrelation must handle 100% of cases.
- Declaratively computing over multiple streams requires support for
AS OFjoins and selects. Without this, users must resort to imperatively windowing streams, and computing over subsets of their data, and other inelegant access patterns.AS OFjoins are rare in modern databases, although well understood and supported in financial databases like kdb+.
In the future, we will expand on these topics and provide greater insight into Materialize’s inner workings. For now, if you’re interested in learning more, check out our architecture overviews. If you want to try it out yourself, check out our getting started guide. And if you’re interested in working on building Materialize, we’re hiring!
